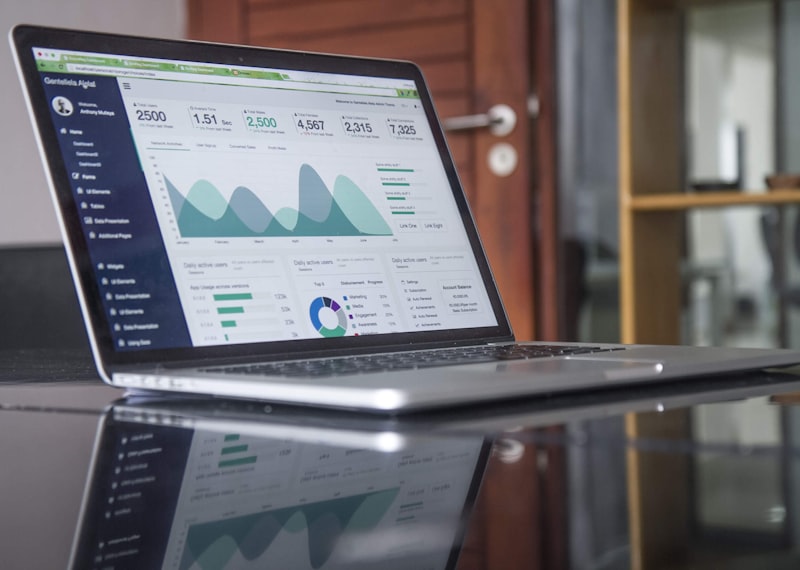
File size compression and parallel loading significantly impact load performance and costs. Discover the optimal configuration for your data pipeline.

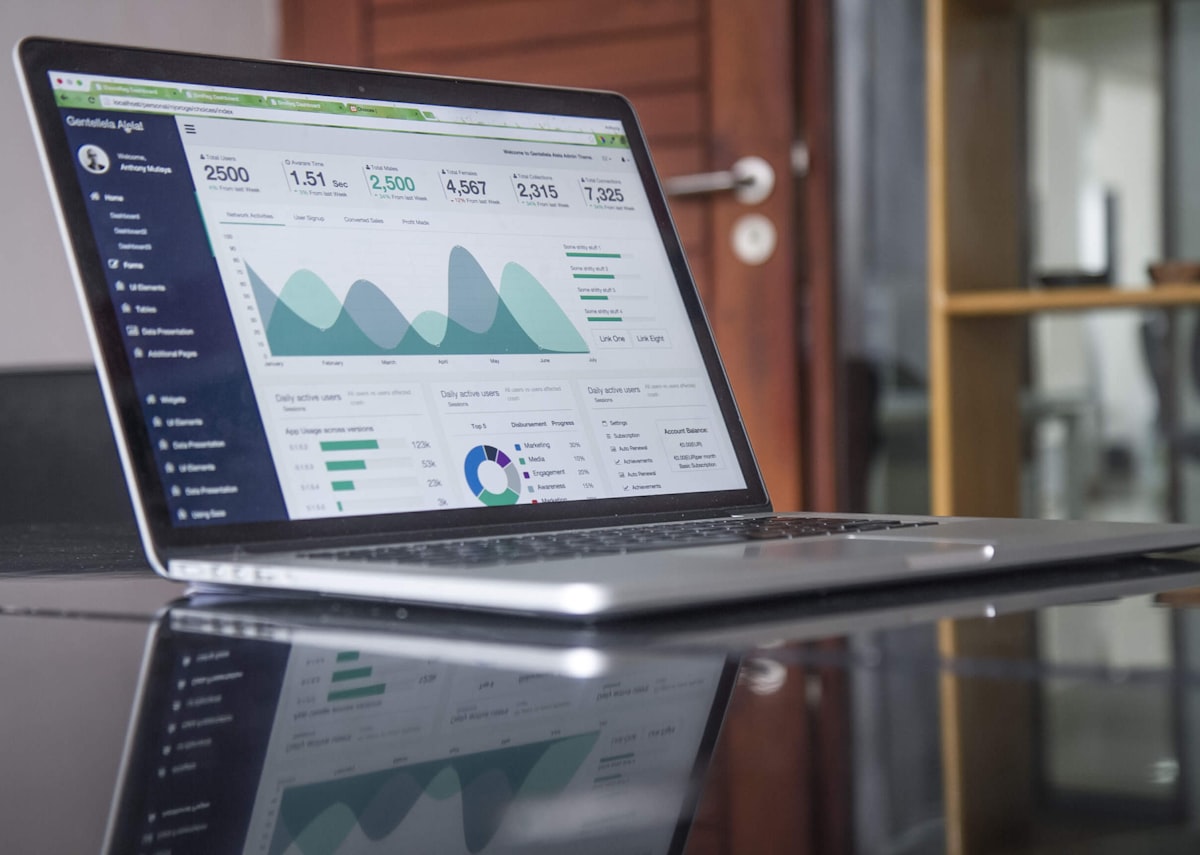
File size, compression, and parallel loading significantly impact load performance and costs. Discover the optimal configuration for your data pipeline.
Many organizations use default COPY settings, loading data inefficiently. This results in slow loads, wasted compute, and higher costs than necessary.
GZIP compression typically provides 3-5x reduction. Comparison:
COPY INTO target_table
FROM @my_stage/path/
FILE_FORMAT = (
TYPE = CSV
COMPRESSION = GZIP
FIELD_DELIMITER = ','
SKIP_HEADER = 1
)
SIZE_LIMIT = 250000000 -- 250MB per file
ON_ERROR = CONTINUE
PURGE = TRUE;
A data engineering team was loading 100GB of daily data using 10 large uncompressed files (10GB each). Loads took 45 minutes and consumed 60 credits. By compressing files with GZIP (reduced to 20GB total), splitting into 80 files of 250MB each, and optimizing COPY settings, load time dropped to 12 minutes and credit consumption to 20 credits - a 67% cost reduction.
Uncover hidden inefficiencies and start reducing Snowflake spend in minutes no disruption, no risk.

Tell us about your Snowflake setup and we’ll take it from there.